[Arxiv 2024-05] Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
Abstract
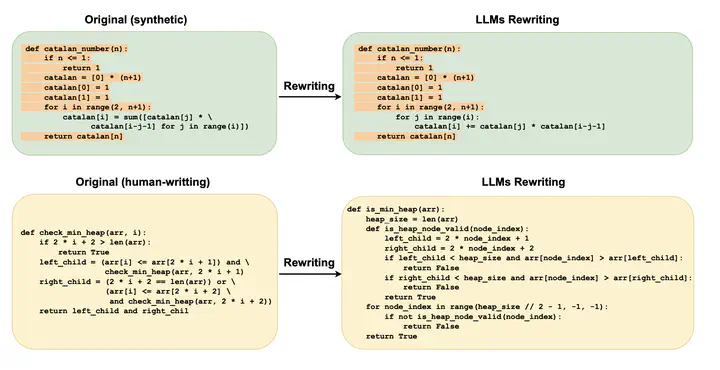
Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive “low-entropy” tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a significant improvement over current synthetic content detectors designed for general texts, achieving a 20.5% increase in AUROC on the APPS benchmark and a 29.1% increase on the MBPP benchmark.
Arxiv Version Link: arXiv